
Python代写 | CMPT 456 Assignment 3
Motivation:
Implement a C++ GUI application that visually depicts the sorting process for several sorting algorithms. Allow the user to select a sort algorithm to be applied to random integer data. Display an “efficiency” metric in the terminal window for the selected sort.
Methodology:
Download and unpack Sort.zip which is used as a template for your implementation. Run the Sort.out executable file either from the terminal or by double-clicking and familiarize yourself with its behavior. Below are several screenshots of the program.

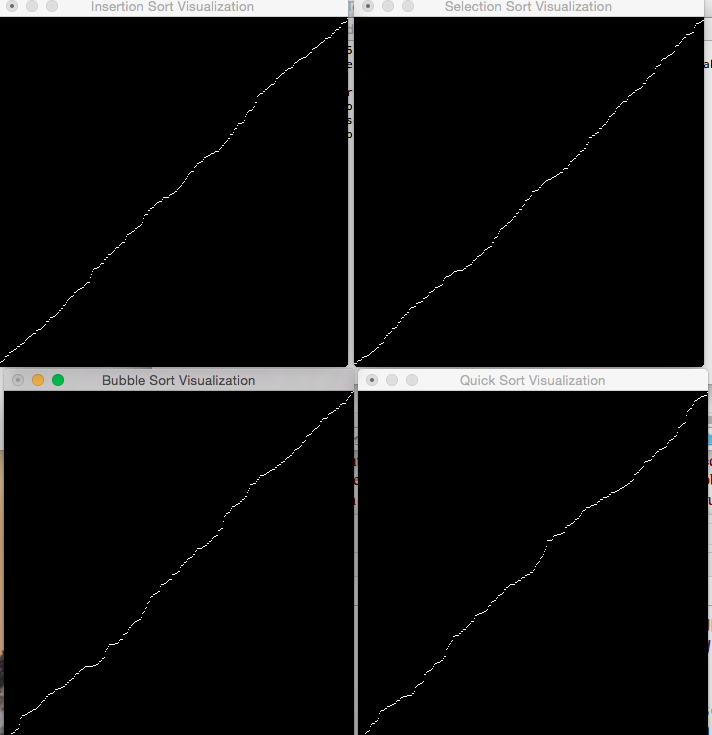
Figure 1: Four GLUT windows each running a different sort algorithm, each has completed its sort on a different random set.
Figure 1 demonstrates four sorting algorithms, each running in a separate GLUT window. Each sort can be restarted using the right mouse button, selecting quit with the right mouse will terminate all windows. A restarted sort destroys the old sorted data set and randomly generates a new data set. An active sorting window must complete its sort before another sorting window can be made active.
Figure 2: Example metric output in terminal.Step1: Implement 4 sorting algorithms in a C++ “Sort” class. You are required to implement four sorts including selection sort and quicksort (these algorithms can be found in the text). Insertion sort has been implemented for you – use this as a template for creating your own sorts – the code includes necessary segments to draw the data set as it is being sorted and to pause (slow down) the animation so you can see the data changing. The fourth sort is your choice – bubble, cocktail, merge or shell are possible choices. Decide what metric you want to measure for each sort, making sure the metric is appropriate for the sort. You might choose to count the number of swaps performed (which is not really relevant for insertion sort since it shifts as opposed to swapping) or it might be more accurate to count the number of comparisons made. Make sure each sort is producing sorted data and a correct metric count.
Step2: Modify the GLUT interface code segments for the fourth sort you choose to implement. As can be seen from figure 1, the sample implements insertion, selection, bubble and quicksort. Thus, the windows and GUI elements are named appropriately.
You must extend the above requirements, here are some possibilities –
- allow the user to select a data set that is ascending, descending or random
- generate multiple metrics, i.e., add stack depth for the recursive sorts
- a better visualization, i.e., draw lines for the data set versus a small quadrilateral – this is very easy to do and is a simple modification of the existing code (see openGL reference in navigation bar)
- Add two more sorting windows with interesting sorts

All work must be received by the due date (source printout, and electronic submission)!
- Handin: Source file printouts.
- Submit Lab3 Folder – name the folder CS200Lab3yourName. The folder should contain an executable file and all source files. Please do not unload XCode projects.
Grading : Quality and correctness of code plus documentation. Correct electronic submission.
本网站支持淘宝 支付宝 微信支付 paypal等等交易。如果不放心可以用淘宝交易!
E-mail:itcsdx@outlook.com 微信:itcsdx
如果您使用手机请先保存二维码,微信识别。如果用电脑,直接掏出手机果断扫描。